Driven by Big Data and cost-effective cloud storage, the hype around Data Lake as an alternative to traditional data warehouse systems gained steam and promised to capture the value of large and complex data assets at scale. In practice, however, Data Lakes quickly turned into data swamps where data from all sources is dumped with minimal regard for data governance best practices. The risks of the swamp sent users headlong back into the battle between data lakes vs data warehouses vs data marts.
Similarly, the schema-on-write construct used to build rigid database models with traditional data warehouse systems also fails to meet the needs of modern Big Data applications. The vast volume, velocity, and variety of Big Data make it challenging to model all information assets in a unified and structured format. And without following an adequate data governance framework, data quality remains elusive, especially as the data is managed and retained in silos and organizations fail to achieve a holistic enterprise-wide view of all of their Big Data assets.
The Open Alternative: What is Data Lakehouse?

Data Lakehouse refers to a new architectural pattern that emerged as an alternative to traditional data warehouse and Data Lake technologies, promising an optimal tradeoff between the two approaches to storing big data. Data Lakehouse offers users an alternative to the battle of Azure data lake vs. data warehouse for ROI.
Data Lakehouse is primarily based on open and direct-access file formats such as the Apache Parquet, supports advanced AI/ML applications, and is designed to overcome the challenges associated with traditional Big Data storage platforms.
The following limitations of Data Warehouse and Data Lakes have driven the need for an open architectural pattern that takes the data structures, management, and quality features from Data Warehouse systems and introduces them to the low-cost cloud storage model employed by the Data Lake technology:
- Lack of Consistency: Data Lake and Data Warehouse systems require high costs and time to maintain data consistency, especially when sourcing large data streams from various sources. For instance, a failure at a single ETL step will likely introduce data quality issues that cascade across the Big Data pipeline.
- Slow Updates and Data Staleness: Storage platforms built on the Data Warehouse architecture suffer from the issue of Data Staleness when frequently updated data takes days to load. As a result, IT is forced to use (relatively) outdated data to make decisions in real-time in a market landscape where proactive decision-making and the agility to act is a key competitive differentiation.
- Data Warehouse Information Loss: Data Warehouse systems maintain a repository of structured databases, but the intense focus on data homogenization negatively affects data quality. Converging all data sources into a single unified format often results in losing valuable data due to incompatibility, lack of integration, and the dynamic nature of Big Data.
Data Lake Governance and Compliance Challenges: Data Lake technology aims to address the challenge by transitioning to the schema-on-read model that allows you to maintain a repository of raw heterogeneous data with multiple formats without a strict structure.
While it can be argued that the stored information is primarily static, any external demands on updating or deleting specific data records are a challenge facing Data Lake environments. There's no easy way to change reference data or index and update a data record within the Data Lake without first scanning the entire repository, which may be required by external compliance laws such as the CCPA and GDPR.
Data Lakehouse Reference Architecture
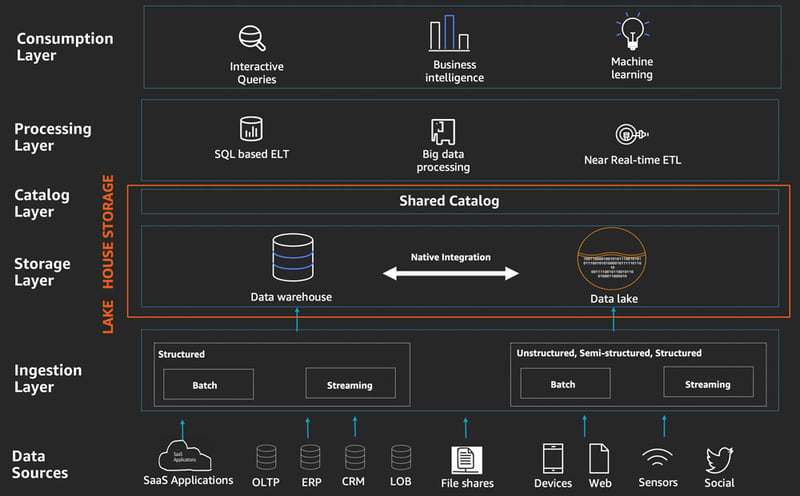
The Data Lakehouse architecture offers the following key capabilities to address the limitations associated with Data Lakes and traditional Data Warehouse systems:
- Schema Enforcement and Evolution allow users to control the evolving database structures and data quality issues.
- Ready for Structured and Unstructured Data allows a wider choice of data management strategies, allowing users to choose between the various schema and models based on applications.
- Open Source Support and Standardization ensure compatibility and integration with multiple platforms.
- Decoupled from the Underlying Infrastructure allows IT to build a flexible, composable cloud infrastructure and provision resources for dynamic workloads without breaking the applications running on it.
- Support for Analytics and Advanced AI Applications to run directly from the Data Lake instead of reformulating copies of information in a data warehouse.
- Optimal Data Quality: Atomicity, Consistency, Isolation, and Durability (ACID) compliance previously available in the Data Warehouse systems ensures data quality as new data is ingested in real-time.
The Data Lakehouse Case Example
We recently worked with a large biotech company struggling to manage an on-premise traditional Oracle-based data platform. The company could not scale new use cases for machine learning teams as new information sources were added, leading to siloed information assets and inadequate data quality.
Following an in-depth 8-week assessment and multiple workshops to understand the company’s true business requirements and Big Data use cases, Mactores worked with their business and IT teams to transform their existing data pipeline and incorporate an advanced Data Lakehouse solution.
Post-implementation resulted in a 10x agility in their DataOps process and a 15x improvement for machine learning applications as teams spent less time fixing data quality issues and more time building business-specific ML use cases. Additionally, the business teams now have access to the self-service platforms to create custom workflows and process new datasets critical to their business decision-making, all independent of the IT team.
Your Data Lakehouse Strategy for the Long-Term
The improvements were largely associated with using the Data Lakehouse architectural pattern to unify robust data management features and advanced analytics capabilities, making critical data accessible to business users from all departments within the organization.
The open format further allowed the company to overcome issues such as performance, inadequate availability, high cost, and vendor lock-in that comes with the increased dependence on proprietary technologies. Stringent regulatory requirements are also met satisfactorily as the Data Lakehouse allows users to upsert, delete, update, and change data records at short notice.
Over the long term, the transition to open-source technologies and the low cost of cloud storage will contribute to the rising popularity of promising new Big Data storage architectural patterns that offer an optimal mix of features from Data Warehouse and Data Lake systems.
As this trend continues to rise, the choice between Data Warehouse, Data Lake, and a Data Lakehouse will largely depend on how well users can maximize data quality and establish a standardized data governance model to achieve the desired ROI on their Big Data applications.
If you are interested in discussing your organization's lake house strategy, let's talk!


