Most teams experimenting with large language models eventually reach the same question: should we fine-tune the model, or can we solve the problem with prompting and retrieval?
In practice, many organizations get this decision wrong. Some teams rush into fine-tuning too early—spending time and GPU resources on training pipelines when prompt engineering or retrieval-augmented generation (RAG) would have been sufficient. Others avoid fine-tuning entirely, even when their applications clearly require deeper model adaptation.
In the first blog of this series, we explored how to build production-grade AI systems using Retrieval-Augmented Generation in “RAG Explained: Architecture, Evaluation, & Production Systems.” That approach works extremely well when the problem is knowledge access, allowing models to retrieve up-to-date information from external data sources.
However, many enterprise use cases require more than just better context.
The confusion usually comes from a misunderstanding of what fine-tuning actually does. Unlike prompt engineering or RAG, which operate at the input level, fine-tuning modifies the model’s internal weights, allowing it to learn new behaviors, reasoning patterns, and domain-specific outputs. This makes it a powerful technique for building production-grade AI systems, but it also introduces new complexities around infrastructure, training data, and deployment.
Fortunately, recent advances in Parameter-Efficient Fine-Tuning (PEFT), especially LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA), have dramatically reduced the cost of customizing large language models. Instead of retraining billions of parameters, these techniques update only a small fraction of the model, enabling teams to fine-tune models with modest GPU resources.
If you prefer a quick walkthrough instead of reading the full guide, feel free to watch the video here, where we explain the main concepts covered in this article.
The Model Adaptation Spectrum
Before implementing fine-tuning, it’s important to understand the spectrum of techniques available for adapting large language models. Not every problem requires modifying the model itself. In many cases, teams can achieve strong results using prompt design or retrieval systems before moving toward more expensive training approaches.
These techniques form a hierarchy, moving from lightweight input-level control to deep model-level modification.

As you move further down this spectrum, three things generally increase:
- Cost
- Infrastructure complexity
- Level of control over the model
The following table summarizes the key trade-offs.
|
Technique |
Cost |
Infrastructure |
Model Control |
|
Prompt Engineering |
Low |
Minimal |
Low |
|
RAG |
Medium |
Vector database + retrieval pipeline |
Medium |
|
LoRA / QLoRA |
Medium |
GPU training environment |
High |
|
Full Fine-Tuning |
High |
Large GPU clusters |
Very High |
|
Continued Pretraining |
Very High |
Distributed training infrastructure |
Maximum |
1. Prompt Engineering
Prompt engineering is the simplest way to adapt an LLM. Instead of changing the model itself, you guide its behavior using carefully designed prompts, instructions, and examples.
This approach works well for:
- prototyping applications
- small behavioral adjustments
- structured prompting tasks
However, prompt engineering has limitations. The model’s underlying reasoning patterns remain unchanged, which means complex domain adaptation can be difficult.
2. Retrieval-Augmented Generation (RAG)
RAG extends prompt engineering by allowing models to retrieve external information from a knowledge base or vector database before generating responses.
This approach is ideal when the problem is primarily knowledge access. For example:
- enterprise document search
- internal knowledge assistants
- customer support systems
Instead of retraining the model, RAG injects relevant context into the prompt during inference.
3. Parameter-Efficient Fine-Tuning (LoRA / QLoRA)
When prompting and retrieval are not enough, teams often move to parameter-efficient fine-tuning (PEFT) techniques such as LoRA or QLoRA.
These approaches modify only a small subset of model parameters, allowing the model to learn new behaviors without retraining billions of weights.
Compared to full fine-tuning, this dramatically reduces:
- GPU memory requirements
- training time
- infrastructure cost
4. Full Fine-Tuning
Full fine-tuning updates all model parameters. This provides maximum control over model behavior but requires significantly more compute.
Training even a 7B parameter model using full fine-tuning can require multiple high-memory GPUs and careful optimization.
5. Continued Pretraining
Continued pretraining (CPT) sits at the far end of the spectrum. Instead of instruction-based fine-tuning, the model is trained on large domain-specific corpora using next-token prediction.
This technique is useful when adapting models to entirely new domains, such as:
- biomedical literature
- financial filings
- legal documents
However, CPT typically requires massive datasets and distributed training infrastructure, making it the most resource-intensive option.
Why RAG Alone Isn’t Enough
Retrieval-Augmented Generation (RAG) is one of the most effective ways to extend large language models with external knowledge. RAG improves factual accuracy but cannot fully eliminate AI hallucinations in complex reasoning tasks. By retrieving relevant documents at inference time, RAG allows models to answer questions using fresh, domain-specific information without retraining the model itself.
However, RAG primarily solves the problem of knowledge retrieval, not behavioral alignment.
A simplified RAG pipeline typically looks like this:
 In production systems, the architecture often includes additional components such as APIs and retrieval layers:
In production systems, the architecture often includes additional components such as APIs and retrieval layers:
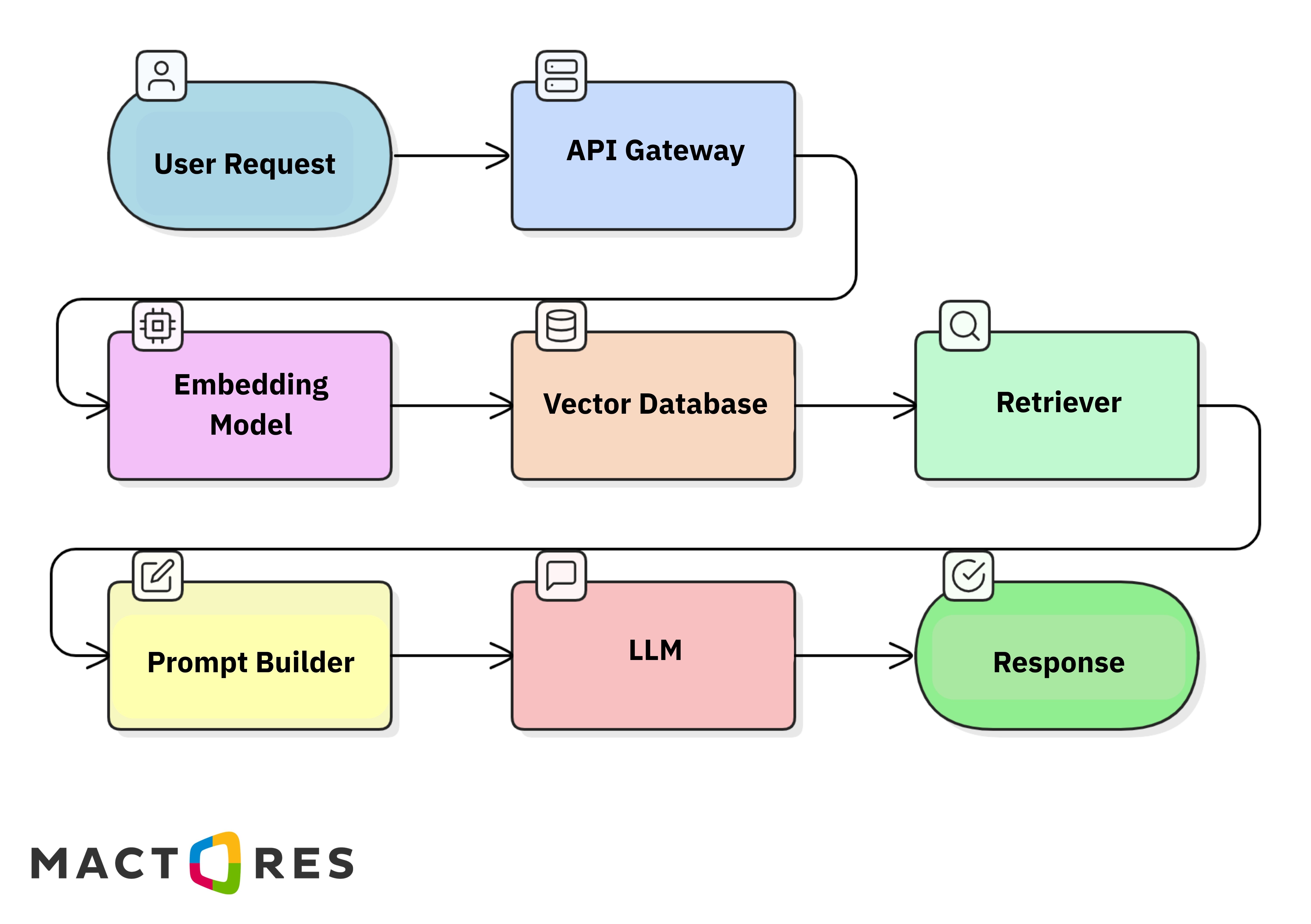
While this approach works extremely well for knowledge access, it has several limitations when building production AI systems.
1. Behavioral Consistency
Some applications require strict and repeatable output formats.
For example, financial analysis tools may require responses in a specific structure for downstream processing.
Example output:
RAG can provide context, but it cannot reliably enforce consistent formatting across responses.
2. Multi-Step Reasoning
RAG improves factual accuracy by injecting relevant documents into the prompt. However, it does not change how the model reasons internally.
If the model struggles with complex reasoning tasks, adding more context will not necessarily fix the issue.
3. Style and Tone Alignment
Many enterprise applications require a consistent communication style.
Examples include:
- customer support assistants
- legal drafting tools
- medical documentation systems
RAG can supply information, but it cannot teach the model to consistently adopt a specific tone or writing style.
4. Structured Outputs
Many production systems require machine-readable responses.
Example:
While prompts can encourage structured outputs, they often remain fragile and inconsistent across generations.
When applications require consistent behavior, reasoning patterns, or structured responses, the solution usually involves modifying the model itself.
This is where fine-tuning techniques like LoRA and QLoRA become necessary.
Parameter-Efficient Fine-Tuning (PEFT)
Traditional fine-tuning updates all parameters in the model. For modern LLMs, this quickly becomes computationally expensive.
For example, a 7B parameter model contains:
Training and updating this many weights requires:
- Large GPU memory
- Long training cycles
- Significant compute cost
For many teams, full fine-tuning is simply not practical at scale.
The PEFT Approach
Parameter-Efficient Fine-Tuning (PEFT) addresses this problem by training small adapter modules instead of updating the entire model.
Instead of modifying the full weight matrix: W ∈ R(d × k)
Where:
A ∈ R(d × r)
B ∈ R(r × k)
Here, r is a small rank value, meaning: r << d, k
This drastically reduces the number of trainable parameters while still allowing the model to learn new behaviors.
This low-rank approximation is the core idea behind LoRA (Low-Rank Adaptation).
Why PEFT Works Well for LLMs
Because the base model remains frozen, only the small adapter layers are trained. This leads to several practical advantages:
- Train less than 1% of model parameters
- Faster training cycles
- Much smaller checkpoints
- Lower GPU memory requirements
As a result, PEFT techniques like LoRA and QLoRA make it possible to fine-tune billion-parameter models using modest GPU infrastructure.
LoRA: Low-Rank Adaptation
LoRA (Low-Rank Adaptation) is one of the most widely used parameter-efficient fine-tuning techniques for large language models. Instead of retraining the entire model, LoRA inserts small trainable matrices into transformer layers.
In a standard transformer attention layer, the input is projected into query, key, and value matrices:
Q = XWq
K = XWk
V = XWv
Here, the weight matrices WqW_qWq, WkW_kWk, and WvW_vWv are part of the base model.
How LoRA Modifies the Layer
LoRA introduces a low-rank update to these weights without modifying the original parameters.
Instead of directly updating WqW_qWq, LoRA applies:
Wq = Wq + ΔWq
ΔWq = BA
Where:
A ∈ R(d × r)
B ∈ R(r × d)
The key idea is that the original model weights remain frozen, and only the small matrices A and B are trained. Because the rank rrr is small, the number of trainable parameters is drastically reduced.
This allows LoRA to adapt the model’s behavior while keeping training efficient.
LoRA Training Pipeline
A typical LoRA training workflow looks like this:
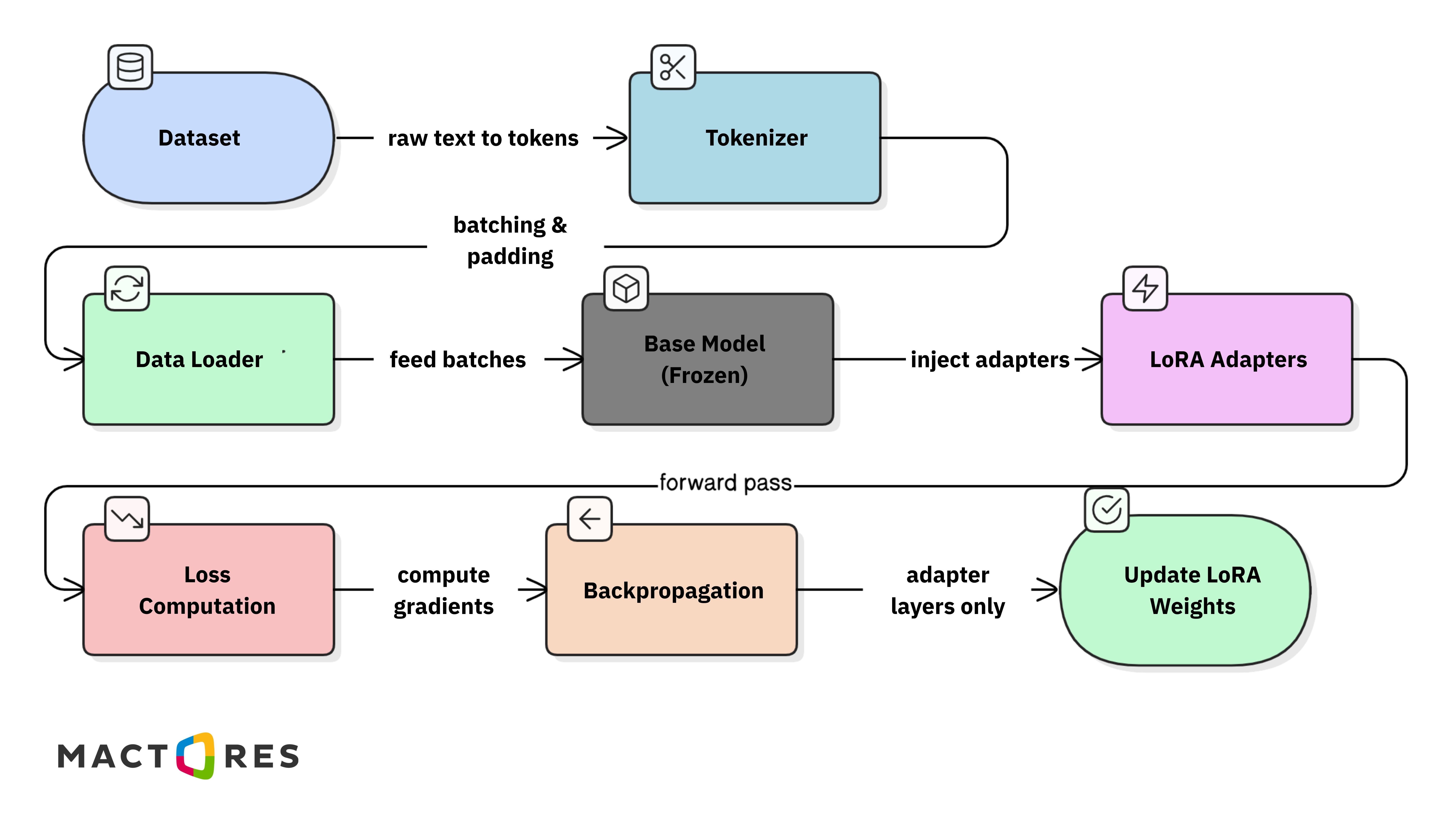
Since only the adapter weights are updated during backpropagation, LoRA significantly reduces GPU memory usage and training time, making it practical to fine-tune large models even on limited infrastructure.
Implementing LoRA with HuggingFace + PEFT
The easiest way to implement LoRA is by using the HuggingFace Transformers ecosystem together with the PEFT (Parameter-Efficient Fine-Tuning) library. These libraries provide built-in support for attaching LoRA adapters to existing transformer models.
Install Dependencies
First, install the required libraries:
These packages handle model loading, adapter injection, distributed training, and memory optimization.
Load the Base Model
Next, load a pretrained model and tokenizer. In this example, we’ll use a 7B LLaMA model.
At this stage, the model loads normally without any fine-tuning adapters.
Configure LoRA
Next, define the LoRA configuration. This determines which layers are modified and how large the adapter matrices will be.
Key parameters include:
- r – the rank of the low-rank matrices
- lora_alpha – scaling factor for weight updates
- target_modules – transformer layers to inject adapters into
Attach LoRA Adapters
Once configured, the adapters can be attached to the base model.
This step inserts the LoRA layers while keeping the original model weights frozen.
Training Setup
Training can then be performed using the HuggingFace Trainer API.
With this configuration, only the LoRA adapter parameters are updated during training, allowing the model to learn new behaviors while keeping compute requirements relatively low.
QLoRA: Memory-Efficient Fine-Tuning
While LoRA significantly reduces the number of trainable parameters, QLoRA goes a step further by reducing the memory footprint of the base model itself.
QLoRA achieves this by loading the base model using 4-bit quantization, while still training LoRA adapters on top of it. This allows large models to be fine-tuned with much smaller GPU memory requirements.
QLoRA relies on three key techniques:
- NF4 Quantization – a 4-bit data type optimized for neural network weights
- Double Quantization – compresses quantization constants to further reduce memory usage
- Paged Optimizers – manages memory spikes during training
Together, these techniques dramatically lower GPU memory consumption.
Memory Comparison
|
Model |
Standard |
QLoRA |
|
7B |
~28 GB |
~6 GB |
|
13B |
~52 GB |
~10 GB |
This makes it possible to fine-tune models that would normally require multiple GPUs using a single high-memory GPU.
Loading a Model with QLoRA
QLoRA is implemented using the BitsAndBytes quantization library.
Once the model is loaded in 4-bit mode, LoRA adapters can be attached in the same way as shown in the previous section. This combination of quantization + low-rank adapters is what makes QLoRA highly efficient for large-scale fine-tuning.
Designing High-Quality Fine-Tuning Data
The success of fine-tuning depends heavily on dataset quality. Even small, well-structured datasets can significantly improve model performance if they clearly demonstrate the desired behavior.
Most modern LLM fine-tuning pipelines use instruction-style or chat-style datasets, where each example represents a conversation between the user and the model.
Recommended Dataset Format
A common format used for chat-based models looks like this:
This structure helps the model learn:
- the role of the system prompt
- the user query pattern
- the expected assistant response
Common Dataset Sources
Training data can come from multiple sources, depending on the application domain:
- Customer support logs
- Internal documentation or knowledge bases
- Domain-specific datasets (finance, legal, medical, etc.)
- Synthetic data generation using larger models
LoRA Hyperparameters Explained
When training LoRA adapters, a few key hyperparameters control how much the model can adapt and how stable the training process is.
Rank (r)
The rank determines the size of the low-rank adapter matrices and directly controls their capacity.
Typical values:
r = 8
r = 16
r = 32
A higher rank allows the adapters to capture more complex patterns, but it also increases the number of trainable parameters.
Alpha
The LoRA alpha parameter controls the scaling of weight updates. It determines how strongly the adapter matrices influence the base model.
A larger alpha increases the contribution of LoRA updates during training.
Target Modules
LoRA adapters are typically injected into specific transformer projection layers.
Common target modules include:
q_proj
v_proj
k_proj
o_proj
In many setups, adapting only q_proj and v_proj provides strong results while keeping the number of trainable parameters small.
Dropout
LoRA also supports adapter dropout, which helps prevent overfitting when training on smaller datasets.
Tuning these parameters allows teams to balance model adaptability, training stability, and compute cost.
Full Fine-Tuning vs LoRA
While LoRA and other PEFT methods are widely used, there are cases where teams still consider full fine-tuning.
Full fine-tuning updates all model parameters, allowing the model to fully adapt to new tasks or domains.
Advantages
- Maximum flexibility in modifying model behavior
- Better performance for deep domain adaptation
- Ability to change internal reasoning patterns
Disadvantages
- Very expensive training
- Requires large GPU clusters
Example GPU Requirements
|
Model |
GPUs |
|
7B |
4× A100 |
|
13B |
8× A100 |
Because of these infrastructure requirements, most teams prefer LoRA or QLoRA for production fine-tuning, reserving full fine-tuning only for cases where deep model adaptation is necessary.
Continued Pretraining (CPT)
Continued Pretraining (CPT) is used when a model needs to learn the language patterns of an entirely new domain. Instead of training on instruction–response examples, the model is trained on large raw text corpora.
Typical datasets include:
- medical research papers
- financial reports and filings
- legal documents and case law
Unlike instruction fine-tuning, CPT uses the standard language modeling objective: predicting the next token in a sequence.
P(w_t | w_1...w_t-1)
During training, the model learns domain-specific terminology, writing patterns, and statistical structure from the dataset.
CPT is usually applied when the domain language differs significantly from the model’s original training data. For example, adapting a general LLM to highly specialized fields like biomedicine, finance, or law often benefits from continued pretraining before applying instruction fine-tuning.
Fine-Tuning LLMs on AWS
For organizations already operating in the AWS ecosystem, fine-tuning pipelines can be integrated directly into existing data engineering and agentic workflows. This is particularly important for regulated industries where data governance, auditability, and security are critical.
At Mactores, many enterprise architectures already rely on services such as Amazon S3, AWS Glue, EMR, and SageMaker for large-scale data processing and machine learning pipelines. Fine-tuning LLMs can be layered into these environments without introducing entirely new infrastructure.
In practice, there are three common approaches for fine-tuning LLMs on AWS, depending on the level of control and operational complexity required.
Option 1: Amazon Bedrock Custom Models
Amazon Bedrock provides a fully managed environment for training and deploying custom foundation models. Teams can upload their datasets and launch training jobs without managing GPUs, containers, or distributed training infrastructure.
Typical workflow:

Advantages
- Minimal infrastructure management
- Built-in enterprise security and governance
- Integrated with other AWS services
This approach is ideal for teams that want fast deployment and simplified operations, especially in regulated environments where managed services reduce operational overhead.
Option 2: SageMaker Training Jobs
For teams that require more flexibility, Amazon SageMaker provides a highly configurable environment for training and deploying fine-tuned models.
Typical architecture:

In many enterprise setups, training datasets are generated through data engineering pipelines using AWS Glue or Amazon EMR, then stored in Amazon S3 before training begins.
A typical SageMaker training job can be launched using the HuggingFace estimator:
This approach allows teams to integrate fine-tuning into broader MLOps pipelines, including experiment tracking, model versioning, and automated deployment.
Option 3: Self-Managed Infrastructure on EC2
Some organizations prefer full control over their infrastructure, particularly when optimizing for performance or cost.
In this setup, teams typically deploy their own training environments using:
- EC2 GPU instances
- Docker containers
- HuggingFace Accelerate for distributed training
- Kubernetes (EKS) for orchestration
This architecture offers maximum flexibility, allowing teams to customize every layer of the training stack, though it also requires more operational expertise.
In practice, many enterprises combine these approaches with existing AWS-native data pipelines, where datasets are prepared using services like AWS Glue or EMR, stored in S3, and then used to train or fine-tune models using Bedrock or SageMaker. This enables organizations to integrate LLM customization directly into their broader cloud data platform.
Deploying Fine-Tuned Models
Once a model has been fine-tuned, the next step is deploying it for production inference. Unlike training workloads, inference systems must be optimized for low latency, high throughput, and scalability, especially when models are integrated into enterprise applications.
A typical production inference architecture looks like this:
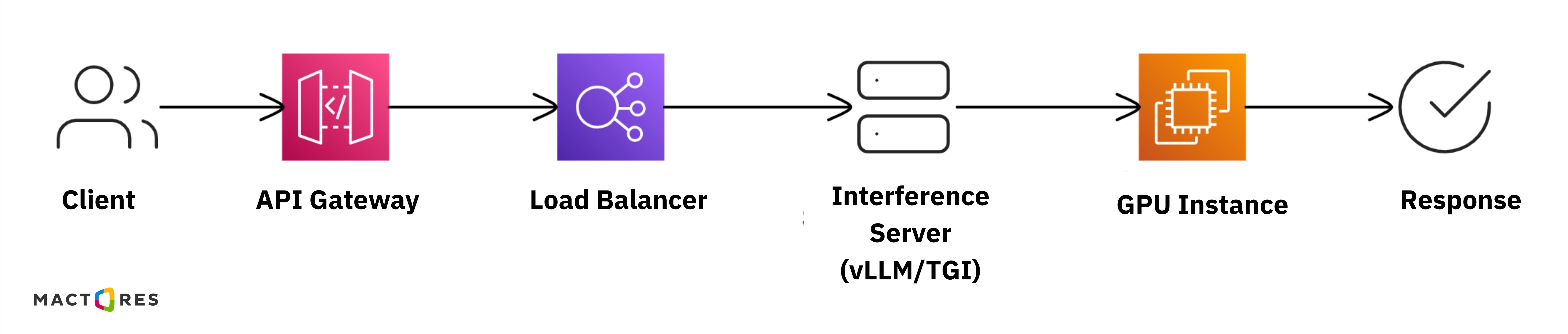
In this setup, user requests are routed through an API layer, distributed by a load balancer, and processed by an inference server running on GPU-backed infrastructure.
In many enterprise deployments, this inference layer sits alongside existing AWS-native data platforms—where data pipelines built with services like Amazon S3, AWS Glue, and Amazon EMR continuously supply data for AI-driven workflows. At Mactores, these architectures are commonly integrated with broader data engineering and cloud modernization initiatives, enabling organizations to operationalize fine-tuned LLMs within their existing analytics and AI ecosystems.
Popular Inference Frameworks
Several frameworks are commonly used for serving large language models in production:
- vLLM – optimized for high-throughput inference with efficient memory management
- Text Generation Inference (TGI) – Hugging Face’s production-ready inference server
- TensorRT-LLM – NVIDIA’s highly optimized runtime for GPU inference
Among these, vLLM has become particularly popular due to its efficient KV cache management and batching capabilities, which significantly improve token generation throughput.
In AWS environments, these inference servers are typically deployed on GPU-backed EC2 instances, SageMaker endpoints, or containerized workloads on Amazon EKS, allowing models to scale dynamically based on application demand while maintaining high availability and performance.
Cost Considerations
One of the main advantages of LoRA and QLoRA is that they significantly reduce the cost of fine-tuning large models compared to full parameter training.
Instead of updating billions of parameters, these methods train only small adapter layers, which lowers both GPU requirements and training time.
Example Training Costs
|
Model |
Method |
Cost |
|
7B |
LoRA |
$20–$80 |
|
13B |
LoRA |
$100–$300 |
|
65B |
QLoRA |
$500+ |
Actual costs vary depending on factors such as dataset size, training duration, and GPU instance type. However, parameter-efficient techniques make it possible to experiment with model customization without requiring large GPU clusters.
Optimization Techniques
Several strategies can further reduce training costs:
- Gradient checkpointing – saves GPU memory by recomputing intermediate activations during backpropagation
- Mixed precision training – uses FP16 or BF16 to accelerate training and reduce memory usage
- Spot instances – leverage discounted AWS GPU capacity for lower-cost training workloads
Together, these optimizations allow teams to fine-tune large models while maintaining cost efficiency and scalable experimentation.
Decision Framework: When to Fine-Tune
Fine-tuning can significantly improve model performance, but it should be used only when simpler approaches are insufficient. Before investing in training infrastructure and datasets, it’s helpful to evaluate whether fine-tuning is actually necessary.
A simple decision framework is to ask the following four questions:
1. Is RAG failing to solve the problem?If retrieval pipelines already provide accurate answers, fine-tuning may not be required.
2. Do you need consistent model behavior or formatting?
Applications that require structured outputs, strict formatting, or controlled tone often benefit from fine-tuning.
3. Do you have high-quality training data?
Fine-tuning works best when you have clean, well-structured examples that clearly demonstrate the desired outputs.
4. Is the improvement worth the compute cost?
Training, evaluation, and deployment introduce additional infrastructure and operational complexity.
Conclusion
If three or more of these answers are yes, fine-tuning is usually a strong candidate for improving your model’s performance in production systems.
In practice, many organizations evaluate these decisions as part of a broader data and AI architecture strategy—balancing retrieval pipelines, model customization, and scalable cloud infrastructure to build reliable enterprise AI systems.
Fine-tuning enables organizations to transform general-purpose LLMs into specialized production systems tailored to specific domains, workflows, and business requirements.
With techniques like LoRA and QLoRA, teams can adapt billion-parameter models without the need for massive GPU infrastructure. When combined with AWS-native training and deployment pipelines, these approaches make it practical to build scalable, production-ready AI systems.
For organizations already operating in AWS environments, integrating fine-tuning into existing data engineering and cloud architectures—such as pipelines built with S3, Glue, EMR, and SageMaker—can unlock powerful new automation capabilities. This is where companies like Mactores help enterprises connect their data platforms, cloud infrastructure, and AI initiatives to operationalize generative AI at scale.


