This blog was first published by same authors on Amazon APN Blogs.
As mentioned in the first post in our series, Seagate Technology asked Mactores Cognition to evaluate and deliver a data platform to process petabytes of data with consistent performance, lower query processing time, lower total cost of ownership (TCO), and the scalability required to support about 2,000 daily users.
Mactores, an AWS Partner Network (APN) Advanced Consulting Partner with the Amazon EMR Service Delivery designation, explored several Amazon EMR capabilities for its Seagate solution. Mactores also holds the AWS Data & Analytics Competency.
We previously described how Seagate used Presto on Amazon EMR to handle queries on 10TB of memory or less. In this post, we describe how to use Apache Hive on Apache Spark for queries larger than 10TB, combined with the use of transient Amazon EMR clusters leveraging Amazon EC2 Spot Instances.
Seagate Technology is a United States-based data storage company with worldwide manufacturing facilities that generate huge amounts of manufacturing and testing data.
With petabytes of data accumulated over 20 years, and more being generated each day, it was imperative for Seagate to have systems in place to ensure the cost of collecting, storing, and processing data did not exceed their return on investment (ROI).
Amazon EMR Capabilities
Amazon EMR is a highly scalable big data platform that supports open source tools such as Apache Spark and Apache Hive.
When you combine Amazon EMR with the dynamic scalability of Amazon Elastic Compute Cloud (Amazon EC2) and scalable storage of Amazon Simple Storage Service (Amazon S3), you get the elasticity to run petabyte-scale analysis for a fraction of the cost of traditional on-premises clusters.
Apache Spark and Hive are natively supported in Amazon EMR, so you can create managed Apache Spark or Apache Hive clusters from the AWS Management Console, AWS Command Line Interface (CLI), or the Amazon EMR API.
Migration Options We Tested
We deployed Mactores’s own comprehensive big data assessment process called HEXA Audit, which performed in-depth analysis of Seagate’s big data requirements.
To reduce the time and cost of the query execution, we recommended transforming Seagate’s current data platform to the Amazon EMR platform. Seagate chose to move forward with two query engines: Apache Hive on Apache Spark and Presto on Amazon EMR.
To meet the query and scale performance requirements, Seagate would use Presto on Amazon EMR for queries less than 10TB of memory. For larger queries, it would use Apache Hive on Apache Spark with the use of transient Amazon EMR clusters leveraging Amazon EC2 Spot Instances to further reduce costs.
Mactores performed a quick proof of concept (PoC) with Seagate data. These are the results we obtained for Amazon EMR with Apache Tools.
Migrating to Amazon EMR with S3 for storage allowed Seagate to keep its compute and storage resources separate, reducing TCO significantly. Queries that used to execute in 7-8 hours on Seagate’s legacy platform now took less than 20 minutes.
Here are some details of the migration:
- Apache MapReduce was the slowest query execution engine due to high disk IO required to process customers’ queries.
- Apache Tez was significantly faster than Apache MapReduce while keeping disk IO the same.
- Apache Spark was slightly faster than Apache Tez with no IO blocking, and was best suited for the solution.
While Spark was fast enough to increase the query processing, it could not match the query execution time Seagate was expecting. Spark, on the other hand, could execute very large queries and jobs that required 10TB of memory or more.
How to Configure Spark as the Execution Engine for Hive
Figure 1 shows the Spark on Hive setup.
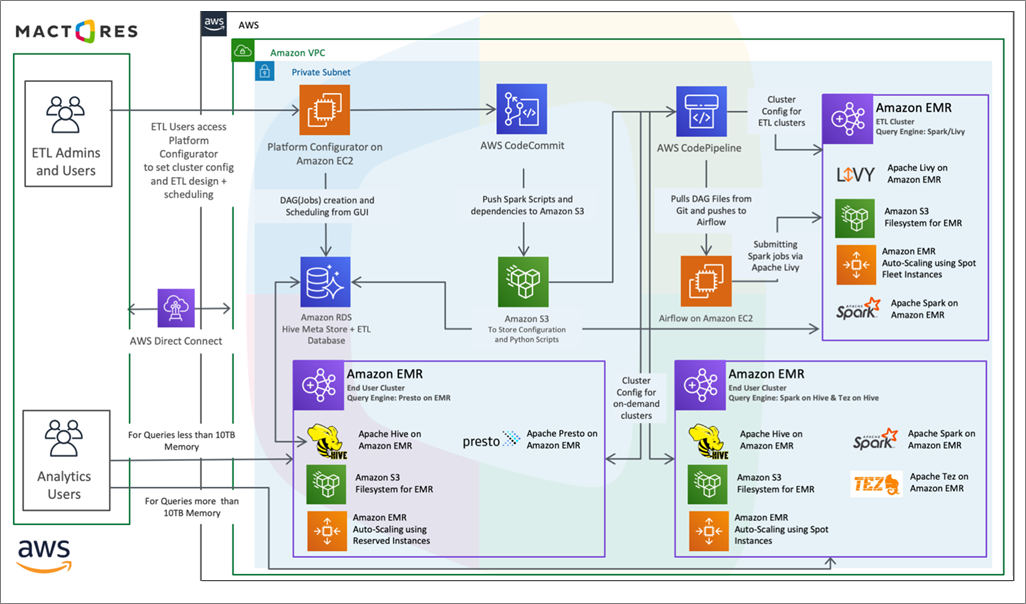
Figure 1 – Overall architectural diagram.
To run Spark as an execution engine in Amazon EMR, we will assume your Amazon EMR cluster is up and running with the services shown in Figure 2.

Figure 2 – Amazon EMR services selected.
We will use Amazon EMR release 5.28, along with the following services:
- Hadoop 2.8.5
- Hive 2.3.4
- Spark 2.4.0
- Tez 0.9.1
- Livy 0.5.0
Figure 3 shows the details of the Amazon EMR cluster, which are:
- Task Node on Demand: – 3 Nodes
- Core Node on Demand: – 3 Nodes
- Task Node Spot Instance with Auto Scaling rule (Apache Hadoop YARN memory available percentage): – Min 3 Max 30 Nodes
- Master Node: – 1

Figure 3 – Amazon EMR cluster details instance group.
Configuration Procedure
To run Hive on Spark, follow these steps.
Step 1: Specify Spark as the execution engine for Hive
Add the following configurations in hive-site.xml at /usr/lib/hive/conf/hive-site.xml, but replace ip-xx-xx-xx-xx.dns.awsuw2.mactores.com with your master IP.
For example, if your master is 10.219.3.112, then replace it with ip-10–219–3–.
<property> <name>hive.execution.engine</name> <value>spark</value> </property> <property> <name>spark.master</name> <value>yarn</value> </property> <property> <name>spark.eventLog.enabled</name> <value>true</value> </property> <property> <name>spark.eventLog.dir</name> <value>/tmp</value> </property> <property> <name>spark.serializer</name> <value>org.apache.spark.serializer.KryoSerializer</value> </property> <property> <name>spark.yarn.jars</name> <value>hdfs://ip-xx-xx-xx-xx.dns.awsuw2.mactores.com:8020/spark-jars/*</value> </property> <property> <name>fs.defaultFS</name> <value>hdfs://ip-xx-xx-xxxx.dns.awsuw2.mactores.com:8020</value> </property> <property> <name>hive.server2.allow.user.substitution</name> <value>true</value> </property> <property> <name>hive.server2.enable.doAs</name> <value>true</value> </property> <property> <name>hive.optimize.sort.dynamic.partition</name <value>true</value> </property> <property> <name>spark.memory.offHeap.size</name> <value>16g</value> </property> <property> <name>spark.memory.offHeap.enabled</name> <value>true</value> </property> <property> <name>spark.eventLog.enabled</name> <value>true</value> </property> <property> <name>spark.logConf</name> <value>true</value> </property> <property> <name>spark.io.compression.codec</name> <value>snappy</value> </property> <property> <name>spark.yarn.MaxAppAttempts</name> <value>5</value> </property> <property> <name>hive.exec.dynamic.partition.mode</name> <value>strict</value> </property> <property> <name>hive.users.in.admin.role</name> <value>root</value> </property> <property> <name>hive.security.authorization.enabled</name> <value>false</value> </property> <property> <name>spark.executor.cores</name> <value>1</value> </property> <property> <name>spark.driver.memory</name> <value>10g</value> </property> <property> <name>spark.executor.memory</name> <value>6g</value> </property> <property> <name>spark.executor.memoryOverhead</name> <value>1g</value> </property> <property> <name>spark.driver.memoryOverhead</name> <value>1g</value> </property> <property> <name>spark.sql.autoBroadcastJoinThreshold</name> <value>1g</value> </property> <property> <name>spark.dynamicAllocation.maxExecutors</name> <value>400</value> </property> <property> <name>spark.dynamicAllocation.enabled</name> <value>true</value> </property> <property> <name>spark.shuffle.service.enabled</name> <value>true</value> </property> <property> <name>hive.metastore.sasl.enabled</name> <value>false</value> </property>
Step 2: Update the JAR paths in yarn-site.xml
Ensure the following properties shown are present in yarn-site.xml. If the properties are missing, please add them.
The JAR paths listed below are required when configuring Spark as the execution engine for Hive. We recommend using absolute paths instead of environmental variables, as environment variables do not work. Also, ensure these paths refer to the Hadoop installation directories.
Replace ip-xx-xx-xx-xx.dns.awsuw2.mactores.com with your master IP. If your master is 10.x.x.x, then replace with ip-10–x–x–x.dns.awsuw2.mactores.com and replace the master-IP address with 10.x.x.x.
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>was <configuration> <property> <name>yarn.web-proxy.address</name> <value>ip-xx-xx-xx-xx.dns.awsuw2.mactores.com:20888</value> </property> <property> <name>yarn.nodemanager.node-labels.provider.configured-node-partition</name> <value>CORE</value> </property> <property> <name>yarn.log.server.url</name> <value>http://ip-xx-xx-xx-xx.dns.awsuw2.mactores.com:19888/jobhistory/logs</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>ip-xx-xx-xx-xx.dns.awsuw2.mactores.com:8032</value> </property> <property> <name>yarn.nodemanager.recovery.supervised</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.client.thread-count</name> <value>64</value> </property> <property> <name>yarn.resourcemanager.nodes.exclude-path</name> <value>/emr/instance-controller/lib/yarn.nodes.exclude.xml</value> </property> <property> <name>yarn.application.classpath</name> <value>$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*,/usr/lib/hadoop-lzo/lib/*,/usr/share/aws/emr/emrfs/conf,/usr/share/aws/emr/emrfs/lib/*,/usr/share/aws/emr/emrfs/auxlib/*,/usr/share/aws/emr/lib/*,/usr/share/aws/emr/ddb/lib/emr-ddb-hadoop.jar,/usr/share/aws/emr/goodies/lib/emr-hadoop-goodies.jar,/usr/share/aws/emr/kinesis/lib/emr-kinesis-hadoop.jar,/usr/lib/spark/yarn/lib/datanucleus-api-jdo.jar,/usr/lib/spark/yarn/lib/datanucleus-core.jar,/usr/lib/spark/yarn/lib/datanucleus-rdbms.jar,/usr/share/aws/emr/cloudwatch-sink/lib/*,/usr/share/aws/aws-java-sdk/*</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>ip-xx-xx-xx-xx.dns.awsuw2.mactores.com:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.client.thread-count</name> <value>64</value> </property> <property> <name>yarn.nodemanager.node-labels.provider</name> <value>config</value> </property> <property> <name>yarn.nodemanager.address</name> <value>${yarn.nodemanager.hostname}:8041</value> </property> <property> <name>yarn.timeline-service.hostname</name> <value>ip-xx-xx-xx-xx.dns.awsuw2.mactores.com</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>172800</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>385024</value> </property> <property> <name>yarn.node-labels.enabled</name> <value>true</value> </property> <property> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>128</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>master-ip_address</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>32</value> </property> <property> <name>yarn.timeline-service.enabled</name> <value>true</value> </property> <property> <name>yarn.node-labels.am.default-node-label-expression</name> <value>CORE</value> </property> <property> <name>yarn.dispatcher.exit-on-error</name> <value>true</value> </property> <property> <name>yarn.timeline-service.http-cross-origin.enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle,</value> </property> <property> <name>yarn.nodemanager.container-metrics.enable</name> <value>false</value> </property> <property> <name>yarn.resourcemanager.system-metrics-publisher.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.client.thread-count</name> <value>64</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>96</value> </property> <property> <name>yarn.nodemanager.local-dirs</name> <value>/mnt/yarn</value> </property> <property> <name>yarn.nodemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/var/log/hadoop-yarn/apps</value> </property> <property> <name>yarn.nodemanager.container-manager.thread-count</name> <value>64</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>241664</value> </property> <property> <name>yarn.nodemanager.localizer.client.thread-count</name> <value>20</value> </property> <property> <name>yarn.scheduler.increment-allocation-mb</name> <value>32</value> </property> <property> <name>yarn.node-labels.fs-store.root-dir</name> <value>/apps/yarn/nodelabels</value> </property> <property> <name>yarn.nodemanager.localizer.fetch.thread-count</name> <value>20</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>5</value> </property> <property> <name>yarn.log-aggregation.enable-local-cleanup</name> <value>false</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>ip-xx-xx-xx-xx.dns.awsuw2.mactores.com:8030</value> </property> <property> <name>yarn.node-labels.configuration-type</name> <value>centralized</value> </property> <property> <name>yarn.nodemanager.log-dirs</name> <value>/var/log/hadoop-yarn/containers</value> </property> <property> <name>yarn.resourcemanager.nodemanager-graceful-decommission-timeout-secs</name> <value>3600</value> </property> <property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>1</value> <final>true</final> </property> <property> <name>yarn.scheduler.capacity.root.default-node-label-expression</name> <value></value> <final>true</final> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> <final>true</final> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> <final>true</final> </property> <property> <name>yarn.nodemanager.disk-health-checker.enable</name> <value>false</value> </property> </configuration>
Link Scala and Spark jars in the Hive lib folder using these commands:
cd $HIVE_HOME/lib ln -s /usr/lib/spark/jars/scala-library*.jar /usr/lib/hive/lib ln -s /usr/lib/spark/jars/spark-core*.jar /usr/lib/hive/lib ln -s /usr/lib/spark/jars/spark-network-common*.jar /usr/lib/hive/lib
Step 3: Verify the symbolic links
Verify the symbolic links by running the ls command:
ls -lsrta /usr/lib/hive/lib
Step 4: Remove the old version of Hive JAR files from the Spark JARs folder
Implement this step according to your version of Hive JAR files in the Spark JARs folder. You can determine the version by looking at the content of $SPARK_HOME/jars folder in this command:
ls /usr/lib/spark/jars/*hive*.jar
For example, if the JARs are of version 1.2.1, remove them using the rm command:
rm /usr/lib/spark/jars/*hive*1.2.1*
Step 5: Copy the new version of Hive JARs to the Spark JARs folder
These JARs are necessary to run Hive with the new Spark. Use the cp command:
cp -r /usr/lib/hive/lib/*hive*.jar /usr/lib/spark/jars
Step 6: Copy Spark JARs on the HDFS park-jars folder
Use these commands:
hadoop fs -mkdir /spark-jars hadoop fs -put $SPARK_HOME/jars/*.jar /spark-jars/
Step 7: Assign the YARN node label
In Amazon EMR, the core node by default has YARN node label ‘CORE’ as a non-exclusive partition. Since the core node is a non-exclusive partition, any other container can be launched in core node. This can lead to inconsistent performance and affect spark engine stability.
To prevent launching the Spark executor container on the core node, you should make it an exclusive partition.
For more information on node partitions:
- Exclusive: Containers will be allocated to nodes with an exact match node partition. For example, asking partition = “x” will be allocated to the node with partition = “x”, while asking DEFAULT partition will be allocated to DEFAULT partition nodes.
- Non-exclusive: If a partition is non-exclusive, it shares an idle resource to the container requesting DEFAULT partition.
Another approach is to assign the YARN node label to all of your task nodes as ‘TASK’ and use this configuration in the Spark submit command:
spark.yarn.am.nodeLabelExpressio='CORE' spark.yarn.executor.nodeLabelExpression='TASK'
Step 8: Restart the following services
To restart the following services, use these commands:
# Stopping yarn sudo stop hadoop-yarn-timelineserver sudo stop hadoop-yarn-resourcemanager sudo stop hadoop-yarn-proxyserver # Stopping hive sudo stop hive-server2 sudo stop hive-hcatalog-server # Stopping spark sudo stop spark-history-server # Starting yarn sudo start hadoop-yarn-timelineserver sudo start hadoop-yarn-resourcemanager sudo start hadoop-yarn-proxyserver # Starting hive sudo start hive-server2 sudo start hive-hcatalog-server # Starting spark sudo start spark-history-server
Step 9: Verify YARN Web UI port 8080
The YARN Node label after the restarting of YARN services should look like this:
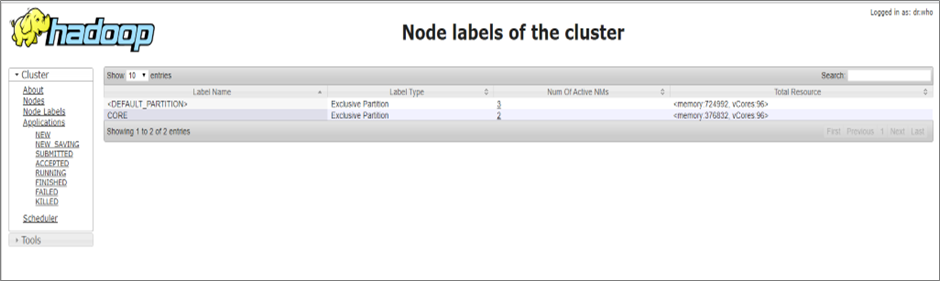
Figure 4 – YARN Node label.
The application queues of YARN should look like this:
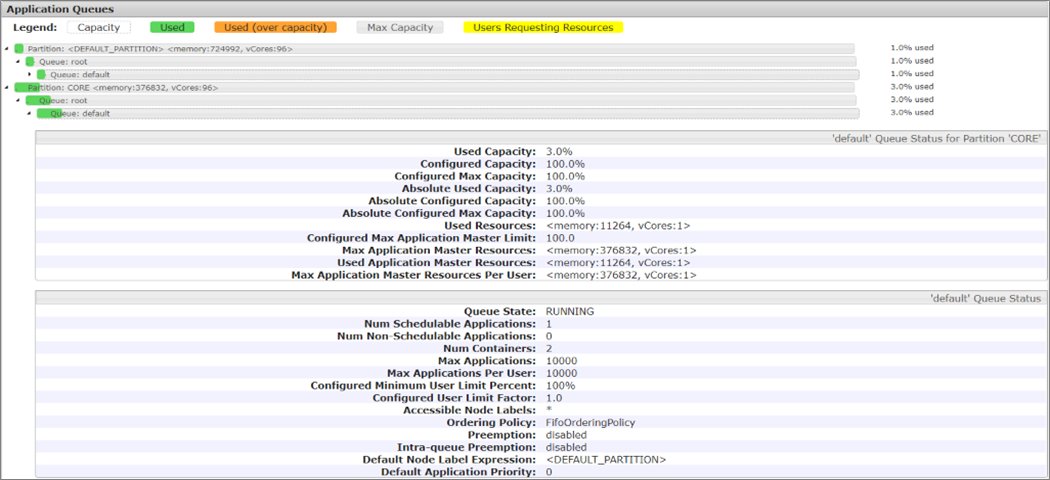
Figure 5 – Application queries.
Step 10: Test Hive on Spark engine
Run count query in Hive on a large table and see how long it takes to complete. It will take some time for the job to start due to the query execution plan, which is being prepared by Hive.
The screen should look like this:
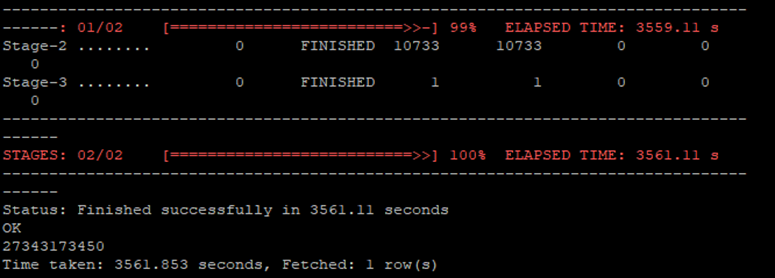
Figure 6 – Hive Shell with Spark as the execution engine.
In the following figure, it can be observed that the application type is “SPARK” and the application name is “Hive on Spark.” Hive engine is responsible to submit Spark jobs in cluster mode, which provides high scalability and stability.
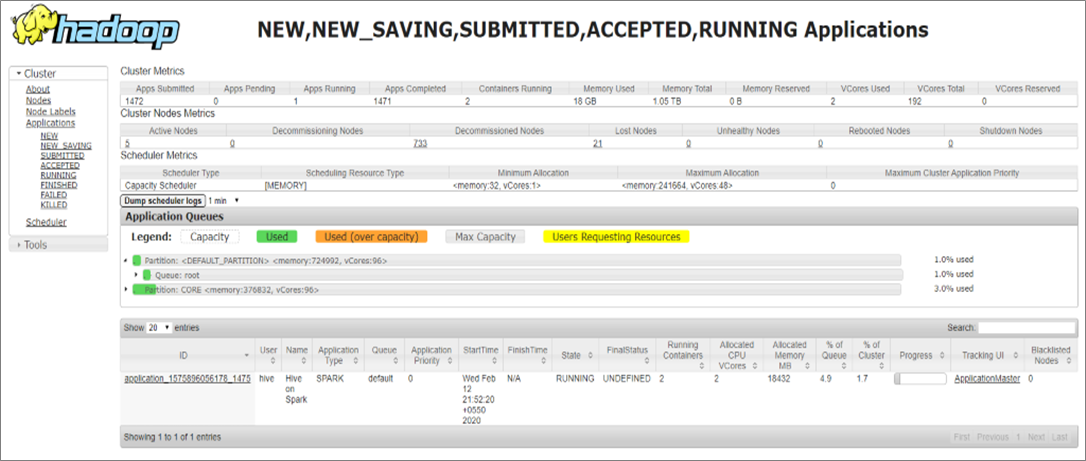
Figure 7 – YARN Web UI after submitting the job in Hive shell.
Results
The chart in Figure 8 is the output of the row count. The execution time of Hive on Spark is 2x less than Hive on Tez and 3x less than Hive on MapReduce.
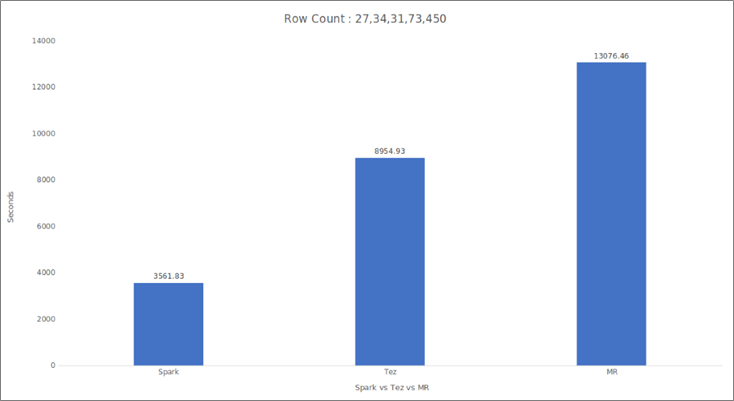
Figure 8 – YARN Web UI after submitting the job in Hive shell.
Hive on Spark is faster than Hive on Tez, but there are also some drawbacks of Hive on Spark:
- We could not visualize a query execution plan on Spark Web UI.
- The query plan generated by Hive was taking too much time.
Those issues were resolved, however, by Apache in the latest release of Hive 3.0.0. Hive has also been upgraded to version 3.0.0 in the latest version (beta) of Amazon EMR 6.0.
Conclusion
Moving to Hive on Spark enabled Seagate to continue processing petabytes of data at scale with significantly lower total cost of ownership. While Seagate achieved lower TCO, the internal users were also experiencing a 2x improvement in the execution time of queries returning 27 trillion rows, as compared to Tez.
Since Mactores deployed the solution with network load balancing, Seagate could switch clusters without impacting end users. Seagate saved an average of 60 percent of CPU time per query, and their end users could get query results in minutes rather than hours, improving the overall efficiency of both their Amazon EMR cluster and business operations.

